
本笔记记录我在实习时经手的项目,主要记录项目亮点、难点、对于项目的思考等
项目代码亮点
使用匿名内部类+静态代码块创建Map
public static final Map<SellOrderTypeEnum, String> SPECIAL_ORDER_TYPE_MAP = new HashMap<SellOrderTypeEnum, String>(4) {
private static final long serialVersionUID = 735789256428542346L;
{
// 支付宝订单
put(SellOrderTypeEnum.ALIPAY_ORDER, DistributionChannelEnum.TAOQUAN_AGENT_ALIPAY.getStr());
put(SellOrderTypeEnum.HAI_WEI_ALIPAY, DistributionChannelEnum.TAOQUAN_AGENT_ALIPAY.getStr());
}
};
流方法的使用
wxPayRouteList.stream().collect(Collectors.toMap(e -> e.getOrderType().name(), Function.identity(), (oldValue, newValue) -> newValue));
- collect方法接收Collectors接口, 接口实现类中的构造方法实际上构造出了一个类似于函数式接口的类, collect方法得到该参数, 将会对该集合的每一个元素都执行Collectors某构造方法的逻辑。
- 在这条语句中, toMap的第一个参数是该集合元素的name,第二个参数是Function的静态方法返回原值(相当于:value->value),第三个参数表示传入一个函数, 该函数在toMap中将会应用至去重。
复杂自定义注解的使用
@CardExchangeLimit(strategy = {
// 兑换码解密错误,次数5次 锁定IP到凌晨
@CardExchangeLimitStrategy(errorCode = ResponseCodeEnum.RQ_CARD_DECRYPT_ERROR, errorMsg = "异常访问,不支持兑换",
limitType = CardExchangeLimitStrategyEntity.LimitType.TEMP, requestTime = 5, timeLimit = false),
// 兑换码不存在(不存在,优惠券,码券状态非正常,兑换扣款),次数10次,锁定1小时
@CardExchangeLimitStrategy(errorCode = {ResponseCodeEnum.RQ_CARD_INVALID,
ResponseCodeEnum.WC_EXCHANGE_NO_REMAIN_AMOUNT,
ResponseCodeEnum.WC_CARD_OVER_TIME,
ResponseCodeEnum.WC_CARD_PWD_INVALID},
errorMsg = "兑换次数过多,请稍后再试", timeUnit = TimeUnit.HOURS,
limitType = CardExchangeLimitStrategyEntity.LimitType.TEMP, limitTime = 1L),
// 一分钟超过某个数量则锁定IP10分钟
// 30分钟超过某个数量则锁定IP10分钟
@CardExchangeLimitStrategy(errorCode = {ResponseCodeEnum.RQ_CARD_SPECIAL_ERROR,
ResponseCodeEnum.WC_CARD_BATCH_STATUS_FROZEN, ResponseCodeEnum.WC_CARD_PWD_USED},
errorMsg = "兑换次数过多,请稍后再试", limitType = CardExchangeLimitStrategyEntity.LimitType.WINDOW),
})
public Page<HaiWeiCouponCommodityVO> queryCardProductByCardPwd(Page<HaiWeiCouponCommodityVO> page, String cardPwd) {
if (StringUtils.isBlank(cardPwd)) {
throw new ErrorCodeException(ResponseCodeEnum.WC_EXCHANGE_FAIL_PARAM_ERROR);
}
// 卡密参数解密
cardPwd = cardPwdDecrypt(cardPwd);
// 校验并查询可兑换产品明细
return haiweiCouponService.queryCardProductByCardPwd(page, cardPwd);
}
- @CardExchangeLimit注解是被切面拦截的注解, 在切面中使用Around模式增强, 首先获取该方法上标注的所有策略, 然后检查其ip地址在redis中的记录的次数。最后在try代码块中执行pont.proceed(); 该方法都执行完成后, 再检查在方法里返回的错误代码, 对其执行对应的策略。
- @CardExchangeLimitStrategy是策略注解, 记录了该被修饰的方法调用时根据某个状态需要执行的动作
- 使用AOP和自定义注解, 减少了重复代码量, 每一个需要该策略模式的方法, 只需要将策略注解标识上即可
Spring的监听机制可能会遇到的问题
最近项目中遇到一个业务场景,就是在Spring容器启动后获取所有的Bean中实现了一个特定接口的对象,第一个想到的是ApplicationContextAware,在setApplicationContext中去通过ctx获取所有的bean,后来发现好像逻辑不对,这个方法不是在所有bean初始化完成后实现的,后来试了一下看看有没有什么Listener之类的,发现了好东西ApplicationListener,然后百度一下ApplicationListener用法,原来有一大堆例子,我也记录一下我的例子好了。
很简单,只要实现ApplicationListener
Java代码
@Component
public class ContextRefreshedListener implements ApplicationListener<ContextRefreshedEvent> {
@Override
public void onApplicationEvent(ContextRefreshedEvent event) {
// 根容器为Spring容器
if(event.getApplicationContext().getParent()==null){
//需要执行的逻辑代码,当spring容器初始化完成后就会执行该方法。
}
}
}
其中,通过event.getApplicationContext().getBeansWithAnnotation获取到所有拥有特定注解的Beans集合,然后遍历所有bean实现业务场景。
总结思考:这样的功能可以实现系统参数的初始化,获取系统中所有接口服务清单等一系列需要在Spring启动后初始化的功能。
ApplicationListener和ContextRefreshedEvent一般都是成对出现的。
事件机制作为一种编程机制,在许多语言中都提供了支持。JAVA语言也不例外,java中的事件机制的参与者有3种角色:
- event object
- event source
- event listener
这三个角色的含义字面上很好解,它们就定义了事件机制的一个基本模型。作为一种常用的编程设计机制,许多开源框架的设计中都使用了事件机制。SpringFramework也不例外。
*在IOC的容器的启动过程,当所有的bean都已经处理完成之后,spring ioc容器会有一个发布事件的动作。从 AbstractApplicationContext 的源码中就可以看出:
protected void finishRefresh() {
// Initialize lifecycle processor for this context.
initLifecycleProcessor();
// Propagate refresh to lifecycle processor first.
getLifecycleProcessor().onRefresh();
// Publish the final event.
publishEvent(new ContextRefreshedEvent(this));
// Participate in LiveBeansView MBean, if active.
LiveBeansView.registerApplicationContext(this);
}
这样,当ioc容器加载处理完相应的bean之后,也给我们提供了一个机会(先有InitializingBean,后有ApplicationListener
org.springframework.context.ApplicationEvent
org.springframework.context.ApplicationListener
一个最简单的方式就是,让我们的bean实现ApplicationListener接口,这样当发布事件时,spring的ioc容器就会以容器的实例对象作为事件源类,并从中找到事件的监听者,此时ApplicationListener接口实例中的onApplicationEvent(E event)方法就会被调用,我们的逻辑代码就会写在此处。这样我们的目的就达到了。但这也带来一个思考,有人可能会想,这样的代码我们也可以通过实现spring的InitializingBean接口来实现啊,也会被spring容器去自动调用,但是大家应该想到,如果我们现在想做的事,是必须要等到所有的bean都被处理完成之后再进行,此时InitializingBean接口的实现就不合适了,所以需要深刻理解事件机制的应用场合。*
曾经有一位同事利用 ApplicationListener,重复加载了好几次 xml 配置文件。所以基础知识一定要掌握。
下面是一个完整的例子:
public class ApplicationContextListener implements
ApplicationListener<ContextRefreshedEvent> {
private static Logger log = LoggerFactory.getLogger
(ApplicationContextListener.class);
@Override
public void onApplicationEvent(ContextRefreshedEvent contextRefreshedEvent){
// root application context
if(null == contextRefreshedEvent.getApplicationContext().getParent()) {
log.debug(">>>>> spring初始化完毕 <<<<<");
// spring初始化完毕后,通过反射调用所有使用BaseService注解的initMapper方法
Map<String, Object> baseServices =
contextRefreshedEvent.getApplicationContext().
getBeansWithAnnotation(BaseService.class);
for(Object service : baseServices.values()) {
log.debug(">>>>> {}.initMapper()", service.getClass().getName());
try {
Method initMapper = service.getClass().getMethod("initMapper");
initMapper.invoke(service);
} catch (Exception e) {
log.error("初始化BaseService的initMapper方法异常", e);
e.printStackTrace();
}
}
Map<String, BaseInterface> baseInterfaceBeans =
contextRefreshedEvent.getApplicationContext().
getBeansOfType(BaseInterface.class);
for(Object service : baseInterfaceBeans.values()) {
_log.debug(">>>>> {}.init()", service.getClass().getName());
try {
Method init = service.getClass().getMethod("init");
init.invoke(service);
} catch (Exception e) {
_log.error("初始化BaseInterface的init方法异常", e);
e.printStackTrace();
}
}
}
}
}
所以,我们的重点来了,我们如果要实现的是在所有的bean都被处理完成之后再进行操作,
就需要实现ApplicationListener
*applicationontext和使用MVC之后的webApplicationontext会两次调用上面的方法,如何区分这个两种容器呢?
但是这个时候,会存在一个问题,在web 项目中(spring mvc),系统会存在两个容器,一个是root application context ,另一个就是我们自己的 projectName-servlet context(作为root application context的子容器)。
这种情况下,就会造成onApplicationEvent方法被执行两次。为了避免上面提到的问题,我们可以只在root application context初始化完成后调用逻辑代码,其他的容器的初始化完成,则不做任何处理,修改后代码*
*@Override
public void onApplicationEvent(ContextRefreshedEvent event) {
if(event.getApplicationContext().getParent() == null){//root application context 没有parent,他就是老大.
//需要执行的逻辑代码,当spring容器初始化完成后就会执行该方法。
}*
*}*
延伸一下:除了以上启动后事件外,还有其他三个事件
Closed在关闭容器的时候调用,
Started理论上在容器启动的时候调用,
Stopped理论上在容器关闭的时候调用。
自定义回调接口通知
场景
- 需要多个类似的场景如支付、退款、下单成功或失败回调(同步或异步都可使用,异步使用最符合场景)
好处
- 代码结构清晰
- 代码解耦,代码中传入对应的实现类后,只需要操作接口即可
- 实现多模块复用
做法
-
定义单方法接口
public interface WxPayEventListener<R extends BaseWxPayResult, T extends BaseWeChatPayRequest> { /** * 请求微信支付中台,获得预下单成功监听 * * @param result BaseWeChatPayRequest 子类 * @param request BaseWxPayResult 子类 */ void onEvent(R result, T request); } -
实现接口
@Component public class DefaultCouponUnifiedListener implements WxPayEventListener<WxPayUnifiedOrderResult, WeChatPayDTO> { @Resource private SellOrderDao sellOrderDao; /** * 下单成功处理 * * @param unifiedOrderResult 下单结果 * @param weChatPayDTO 下单参数 */ @Override public void onEvent(WxPayUnifiedOrderResult unifiedOrderResult, WeChatPayDTO weChatPayDTO) { log.info("卡券订单统一下单成功,赋值 prepay_id,订单批次号:{},prepay_id:{}", weChatPayDTO.getBatchNo(), unifiedOrderResult.getPrepayId()); sellOrderDao.updatePayId(weChatPayDTO.getBatchNo(), unifiedOrderResult.getPrepayId()); } } -
实际业务场景中组装参数,传入需要执行操作的方法中
WeChatPayDTO weChatPayDTO = WeChatPayDTO.builder() ...... .payUnifiedEvent(hwDefaultCouponUnifiedListener) .build(); wxPayResultSet = commonWxPayComponent.h5WeChatPay(weChatPayDTO); -
执行操作的方法中,执行完核心逻辑后,回调执行下通知事件
// 通知事件
WxPayEventListener<WxPayUnifiedOrderResult, WeChatPayDTO> payEvent = dto.getPayUnifiedEvent();
// 通知接口下单结果
if (payEvent != null) {
payEvent.onEvent(result, dto);
}
方法参数解析器HandlerMethodArgumentResolver
-
解析器可以配合interceptor,(Spring也向我们提供了多种解析器Resolver,如用来统一处理异常的HandlerExceptionResolver和用来处理方法参数的解析器HandlerMethodArgumentResolver)
-
包含2个方法: supportsParameter(满足某种要求,返回true,方可进入resolveArgument做参数处理)和resolveArgument(实参的具体处理方法)
-
对需要处理的参数使用自己的自定义注解, 然后在解析器的条件方法中使用其判断
@Override public boolean supportsParameter(MethodParameter methodParameter) { //如果函数包含我们的自定义注解,那就走resolveArgument()函数 return methodParameter.hasParameterAnnotation(Params.class); }然后就可以对参数进行处理(案例如:客户端未传值,设置默认值。权限校验)
-
同时需要在WebMvcConfigurerAdapter添加HandlerMethodArgumentResolver
@Configuration public class ApplicationConfigurer extends WebMvcConfigurerAdapter { @Override public void addArgumentResolvers(List<HandlerMethodArgumentResolver> argumentResolvers) { super.addArgumentResolvers(argumentResolvers); argumentResolvers.add(new TestArgumentResolver()); } } -
https://blog.csdn.net/songzehao/article/details/99641594 用于统一获取当前登录用户的案例
第三方接口类交给Spring管理要用Configuration
Spring Boot之Filter和Interceptor的对比分析
- 两者实现的功能和目的是一样的,都是用来拦截和处理Http请求,在请求到达真实的业务逻辑处理阶段,比如用户登录的认证过程等。
- Filter是在Java Web应用中的拦截器,一般服务于以下流程:HttpRequest —-> Filter —-> Servlet —-> Controller/Action/… —-> Filter —-> HttpResponse
- Filter的作用就是在用户请求到达Servlet之前,进行拦截。在拦截到用户的请求后,我们可以实现一些自定义的业务逻辑,也可以针对服务器的响应数据进行修改。
- Interceptor在许多Java Web框架中都有应用,在这些框架中都实现拦截器Interceptor。例如Struts2中的Interceptor、Spring MVC中的HandlerInterceptor等。相比于Filter,这些框架中的Interceptor的产生作用的时间和位置不一样,下面描述了应用了Spring MVC中的HandlerInterceptor的web请求流程:HttpRequest —-> DispactherServlet —-> HandlerInterceptor —->Controller—-> HandlerInterceptor —-> HttpResponse
- Filter的作用区间在请求到达Servlet之前,Interceptor在请Dispatcher接收到用户请求之后,先于具体的业务逻辑操作。
- Filter面对的所有的请求,无差别;Interceptor是面对具体的Controller。
- Filter先于Interceptor发生,Filter可以通过返回False的逻辑判断来中断当前的请求逻辑。
- 两者的主要应用场景相同,比如用户登录认证,请求记录历史,session的检查和处理等等共有的行为和操作检查信息。
不同之处在于,如果使用Spring框架,比如Spring Boot/Spring MVC之类的,则建议使用Interceptor。如果并未使用任何框架,只是简单的Web应用和Servlet,则可以使用Filter。 - Filter是在Java Web发展早期使用比较多的过滤器,随着Spring的发展和兴起,则Interceptor随着Spring而逐渐更为大家所熟知和使用。本质上两者并无不同之处,功能也是类似和相同的。
SpringMVC 中 @ControllerAdvice 注解的三种使用场景
全局异常处理
使用 @ControllerAdvice 实现全局异常处理,只需要定义类,添加该注解即可定义方式如下:
@ControllerAdvice
public class MyGlobalExceptionHandler {
@ExceptionHandler(Exception.class)
public ModelAndView customException(Exception e) {
ModelAndView mv = new ModelAndView();
mv.addObject("message", e.getMessage());
mv.setViewName("myerror");
return mv;
}
}
在该类中,可以定义多个方法,不同的方法处理不同的异常,例如专门处理空指针的方法、专门处理数组越界的方法...,也可以直接向上面代码一样,在一个方法中处理所有的异常信息。
@ExceptionHandler 注解用来指明异常的处理类型,即如果这里指定为 NullpointerException,则数组越界异常就不会进到这个方法中来。
全局数据绑定
全局数据绑定功能可以用来做一些初始化的数据操作,我们可以将一些公共的数据定义在添加了 @ControllerAdvice 注解的类中,这样,在每一个 Controller 的接口中,就都能够访问导致这些数据。
使用步骤,首先定义全局数据,如下:
@ControllerAdvice
public class MyGlobalExceptionHandler {
@ModelAttribute(name = "md")
public Map<String,Object> mydata() {
HashMap<String, Object> map = new HashMap<>();
map.put("age", 99);
map.put("gender", "男");
return map;
}
}
使用 @ModelAttribute 注解标记该方法的返回数据是一个全局数据,默认情况下,这个全局数据的 key 就是返回的变量名,value 就是方法返回值,当然开发者可以通过 @ModelAttribute 注解的 name 属性去重新指定 key。
定义完成后,在任何一个Controller 的接口中,都可以获取到这里定义的数据:
@RestController
public class HelloController {
@GetMapping("/hello")
public String hello(Model model) {
Map<String, Object> map = model.asMap();
System.out.println(map);
int i = 1 / 0;
return "hello controller advice";
}
}
全局数据预处理
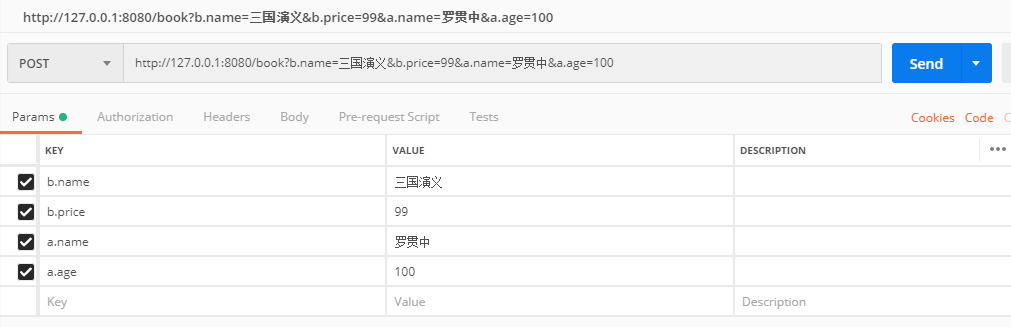
考虑我有两个实体类,Book 和 Author,分别定义如下:
public class Book {
private String name;
private Long price;
//getter/setter
}
public class Author {
private String name;
private Integer age;
//getter/setter
}
此时,如果我定义一个数据添加接口,如下:
@PostMapping("/book")
public void addBook(Book book, Author author) {
System.out.println(book);
System.out.println(author);
}
这个时候,添加操作就会有问题,因为两个实体类都有一个 name 属性,从前端传递时 ,无法区分。此时,通过 @ControllerAdvice 的全局数据预处理可以解决这个问题
解决步骤如下:
1.给接口中的变量取别名
@PostMapping("/book")
public void addBook(@ModelAttribute("b") Book book, @ModelAttribute("a") Author author) {
System.out.println(book);
System.out.println(author);
}
2.进行请求数据预处理
在 @ControllerAdvice 标记的类中添加如下代码:
@InitBinder("b")
public void b(WebDataBinder binder) {
binder.setFieldDefaultPrefix("b.");
}
@InitBinder("a")
public void a(WebDataBinder binder) {
binder.setFieldDefaultPrefix("a.");
}
@InitBinder("b") 注解表示该方法用来处理和Book和相关的参数,在方法中,给参数添加一个 b 前缀,即请求参数要有b前缀.
3.发送请求
请求发送时,通过给不同对象的参数添加不同的前缀,可以实现参数的区分.
TransactionSynchronizationManager用法和含义
当我们有业务需要在事务提交过后进行某一项或者某一系列的业务操作时候我们就可以使用TransactionSynchronizationManager
通过spring的aop机制将需要进行后置业务处理的操作,提交给spring的处理机制,并且切入到事务处理的后面
TransactionSynchronizationManager这个类中由一系列的ThreadLocal ,我们需要关注的是synchronizations,在后面使用到的TransactionSynchronizationManager.isSynchronizationActive()、TransactionSynchronizationManager.registerSynchronization()和new TransactionSynchronizationAdapter(),都与它密切有关。
在Spring在开启数据库事务(无论是使用@Transactional注解,还是用xml配置)时,都会向其中写入一个实例,用于自动处理Connection的获取、提交或回滚等操作。

再看isSynchronizationActive()方法,判断了synchronizations中是否有数据(Set
再看registerSynchronization()方法,首先调用isSynchronizationActive()做一个校验;然后将入参synchronization添加到synchronizations 中。入参synchronization中的方法不会在这里执行,而是要等到事务执行到特定阶段时才会被调用。

TransactionSynchronizationAdapter是一个适配器:它实现了TransactionSynchronization接口,并为每一个接口方法提供了一个空的实现。这类适配器的基本思想是:接口中定义了很多方法,然而业务代码往往只需要实现其中一小部分。利用这种“空实现”适配器,我们可以专注于业务上需要处理的回调方法,而不用在业务类中放大量而且重复的空方法。
结合TransactionSynchronizationManager和TransactionSynchronizationAdapter利用ThreadPoolExecutor实现一个事务后多线程处理功能。
/**
* 事务提交异步线程
*
* @author ly
*/
public class TransactionAfterCommitExecutor extends ThreadPoolExecutor {
private static final Logger LOGGER = LoggerFactory.getLogger(TransactionAfterCommitExecutor.class);
public TransactionAfterCommitExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue) {
super(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue);
}
/////
public TransactionAfterCommitExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory) {
super(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue, threadFactory);
}
public TransactionAfterCommitExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, RejectedExecutionHandler handler) {
super(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue, handler);
}
public TransactionAfterCommitExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler) {
super(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue, threadFactory, handler);
}
private ThreadLocal<List<Runnable>> currentRunables = new ThreadLocal<List<Runnable>>(){
@Override
protected List<Runnable> initialValue() {
return new ArrayList<>(5);
}
};
private ThreadLocal<Boolean> registed = new ThreadLocal<Boolean>(){
@Override
protected Boolean initialValue() {
return false;
}
};
/**
* 默认策略丢弃最老的数据
*/
public TransactionAfterCommitExecutor() {
this(
50, 500,
500L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(1024),
new ThreadFactoryBuilder().setNameFormat("transaction-after-commit-call-pool-%d").build(),
new ThreadPoolExecutor.DiscardOldestPolicy());
}
@Override
public void execute(final Runnable runnable) {
//如果事务同步未启用则认为事务已经提交,马上进行异步处理
if (!TransactionSynchronizationManager.isSynchronizationActive()) {
super.execute(runnable);
} else {
//同一个事务的合并到一起处理
currentRunables.get().add(runnable);
//如果存在事务则在事务结束后异步处理
if(!registed.get()){
TransactionSynchronizationManager.registerSynchronization(new AfterCommitTransactionSynchronizationAdapter());
registed.set(true);
}
}
}
@Override
public Future<?> submit(final Runnable runnable) {
//如果事务同步未启用则认为事务已经提交,马上进行异步处理
if (!TransactionSynchronizationManager.isSynchronizationActive()) {
return super.submit(runnable);
} else {
final RunnableFuture<Void> ftask = newTaskFor(runnable, null);
//如果存在事务则在事务结束后异步处理
TransactionSynchronizationManager.registerSynchronization(new TransactionSynchronizationAdapter() {
@Override
public void afterCommit() {
TransactionAfterCommitExecutor.super.submit(ftask);
}
});
return ftask;
}
}
private class AfterCommitTransactionSynchronizationAdapter extends TransactionSynchronizationAdapter{
@Override
public void afterCompletion(int status) {
final List<Runnable> txRunables = new ArrayList<>(currentRunables.get());
currentRunables.remove();
registed.remove();
if(status == STATUS_COMMITTED){
TransactionAfterCommitExecutor.super.execute(new Runnable() {
@Override
public void run() {
for (Runnable runnable : txRunables) {
try {
runnable.run();
} catch (Exception e) {
LOGGER.error("ex:",e);
}
}
}
});
}
}
}
}
Spring中的@Async的用法
在Java应用中,绝大多数情况下都是通过同步的方式来实现交互处理的;但是在处理与第三方系统交互的时候,容易造成响应迟缓的情况,之前大部分都是使用多线程来完成此类任务,其实,在spring 3.x之后,就已经内置了@Async来完美解决这个问题,本文将完成介绍@Async的用法。
1. 何为异步调用?
在解释异步调用之前,我们先来看同步调用的定义;同步就是整个处理过程顺序执行,当各个过程都执行完毕,并返回结果。 异步调用则是只是发送了调用的指令,调用者无需等待被调用的方法完全执行完毕;而是继续执行下面的流程。
例如, 在某个调用中,需要顺序调用 A, B, C三个过程方法;如他们都是同步调用,则需要将他们都顺序执行完毕之后,方算作过程执行完毕; 如B为一个异步的调用方法,则在执行完A之后,调用B,并不等待B完成,而是执行开始调用C,待C执行完毕之后,就意味着这个过程执行完毕了。
2. 常规的异步调用处理方式
在Java中,一般在处理类似的场景之时,都是基于创建独立的线程去完成相应的异步调用逻辑,通过主线程和不同的线程之间的执行流程,从而在启动独立的线程之后,主线程继续执行而不会产生停滞等待的情况。
3. @Async介绍
在Spring中,基于@Async标注的方法,称之为异步方法;这些方法将在执行的时候,将会在独立的线程中被执行,调用者无需等待它的完成,即可继续其他的操作。
如何在Spring中启用@Async
- 基于Java配置的启用方式:
@Configuration
@EnableAsync
public class SpringAsyncConfig { ... }
- 基于XML配置文件的启用方式,配置如下:
<task:executor id="myexecutor" pool-size="5" />
<task:annotation-driven executor="myexecutor"/>
以上就是两种定义的方式。
4. 基于@Async无返回值调用
示例如下:
@Async //标注使用
public void asyncMethodWithVoidReturnType() {
System.out.println("Execute method asynchronously. "
+ Thread.currentThread().getName());
}
使用的方式非常简单,一个标注即可解决所有的问题。
5. 基于@Async返回值的调用
示例如下:
@Async
public Future<String> asyncMethodWithReturnType() {
System.out.println("Execute method asynchronously - "
+ Thread.currentThread().getName());
try {
Thread.sleep(5000);
return new AsyncResult<String>("hello world !!!!");
} catch (InterruptedException e) {
//
}
return null;
}
以上示例可以发现,返回的数据类型为Future类型,其为一个接口。具体的结果类型为AsyncResult,这个是需要注意的地方。
调用返回结果的异步方法示例:
public void testAsyncAnnotationForMethodsWithReturnType()
throws InterruptedException, ExecutionException {
System.out.println("Invoking an asynchronous method. "
+ Thread.currentThread().getName());
Future<String> future = asyncAnnotationExample.asyncMethodWithReturnType();
while (true) { ///这里使用了循环判断,等待获取结果信息
if (future.isDone()) { //判断是否执行完毕
System.out.println("Result from asynchronous process - " + future.get());
break;
}
System.out.println("Continue doing something else. ");
Thread.sleep(1000);
}
}
分析: 这些获取异步方法的结果信息,是通过不停的检查Future的状态来获取当前的异步方法是否执行完毕来实现的。
6. 基于@Async调用中的异常处理机制
在异步方法中,如果出现异常,对于调用者caller而言,是无法感知的。如果确实需要进行异常处理,则按照如下方法来进行处理:
- 自定义实现AsyncTaskExecutor的任务执行器
在这里定义处理具体异常的逻辑和方式。
-
配置由自定义的TaskExecutor替代内置的任务执行器
示例步骤1,自定义的TaskExecutor
public class ExceptionHandlingAsyncTaskExecutor implements AsyncTaskExecutor {
private AsyncTaskExecutor executor;
public ExceptionHandlingAsyncTaskExecutor(AsyncTaskExecutor executor) {
this.executor = executor;
}
////用独立的线程来包装,@Async其本质就是如此
public void execute(Runnable task) {
executor.execute(createWrappedRunnable(task));
}
public void execute(Runnable task, long startTimeout) {
/用独立的线程来包装,@Async其本质就是如此
executor.execute(createWrappedRunnable(task), startTimeout);
}
public Future submit(Runnable task) { return executor.submit(createWrappedRunnable(task));
//用独立的线程来包装,@Async其本质就是如此。
}
public Future submit(final Callable task) {
//用独立的线程来包装,@Async其本质就是如此。
return executor.submit(createCallable(task));
}
private Callable createCallable(final Callable task) {
return new Callable() {
public T call() throws Exception {
try {
return task.call();
} catch (Exception ex) {
handle(ex);
throw ex;
}
}
};
}
private Runnable createWrappedRunnable(final Runnable task) {
return new Runnable() {
public void run() {
try {
task.run();
} catch (Exception ex) {
handle(ex);
}
}
};
}
private void handle(Exception ex) {
//具体的异常逻辑处理的地方
System.err.println("Error during @Async execution: " + ex);
}
}
分析: 可以发现其是实现了AsyncTaskExecutor, 用独立的线程来执行具体的每个方法操作。在createCallable和createWrapperRunnable中,定义了异常的处理方式和机制。
handle()就是未来我们需要关注的异常处理的地方。
配置文件中的内容:
1 <task:annotation-driven executor="exceptionHandlingTaskExecutor" scheduler="defaultTaskScheduler" />
2 <bean id="exceptionHandlingTaskExecutor" class="nl.jborsje.blog.examples.ExceptionHandlingAsyncTaskExecutor">
3 <constructor-arg ref="defaultTaskExecutor" />
4 </bean>
5 <task:executor id="defaultTaskExecutor" pool-size="5" />
6 <task:scheduler id="defaultTaskScheduler" pool-size="1" />
分析: 这里的配置使用自定义的taskExecutor来替代缺省的TaskExecutor。
7. @Async调用中的事务处理机制
在@Async标注的方法,同时也适用了@Transactional进行了标注;在其调用数据库操作之时,将无法产生事务管理的控制,原因就在于其是基于异步处理的操作。
那该如何给这些操作添加事务管理呢?可以将需要事务管理操作的方法放置到异步方法内部,在内部被调用的方法上添加@Transactional.
例如: 方法A,使用了@Async/@Transactional来标注,但是无法产生事务控制的目的。
方法B,使用了@Async来标注, B中调用了C、D,C/D分别使用@Transactional做了标注,则可实现事务控制的目的。
线上项目OOM的问题
-
原因
原因是在判断库存的业务逻辑中,查询整个数据库表对应商品存放到list中,然后再判断大小,导致在业务繁忙时大小为几十万的List大对象直接进入old区,导致堆内存无法扩展,抛出OOM错误
-
排查方法
- JDK工具包下的visualVM,查看正在运行的项目堆栈内存占用情况
- 使用eclipse dump分析工具, 分析内存溢出时,JVM内存占用情况
-
反思
涉及到从数据库拿取大量数据存放到数据结构时需谨慎,一般的计算尽量在数据库层面就解决
SQL
Exists
select count(*)
from tbl_commodity c,
tbl_commodity_type t
where c.commodity_type_id = t.id
and c.sell_status = 'ON'
and t.shelf_status = 'ON'
and ((c.commodity_property = 'TICKET' and exists(select t.id
from tbl_ticket t
where t.commodity_id = c.id
and t.ticket_status in ( 'NORMAL', 'FREEZE', 'AFTER_SALE' )))
or (c.commodity_property = 'CARD' and exists(select tc.id
from tbl_card tc
where tc.commodity_id = c.id
and tc.card_status in( 'NORMAL', 'FREEZE', 'AFTER_SALE' ))))
外面小表,里面大表时使用,先查询出小表的一条数据,根据这一条数据在大表中的索引查询到大表中的一条,再判断这一条数据的状态
活用left join
SELECT
r.id,
r.coupon_id couponId,
r.order_id orderId,
r.order_type orderType,
r.commodity_id commodityId,
hc.bind_mobile bindMobile,
hc.coupon_number couponNumber,
hc.coupon_pwd couponPwd,
cb.batch_no batchNo,
IFNULL( so.order_no, ro.order_no ) relateOrderNo,
a.account agentAccount,
a.agent_name agentName,
ct.type_name typeName,
commodity.commodity_name commodityName,
IF
( r.order_type = 'SELL_ORDER', 'COUPON', 'RECHARGE' ) orderCategory,
so.order_status orderStatus,
'' rechargeAccount,
so.amount payPrice,
hc.remark,
r.create_time createTime,
ifnull(
CASE
WHEN commodity.commodity_property = 'TICKET' THEN
( SELECT cost FROM tbl_ticket tt WHERE tt.id = so.ticket_id ) ELSE ( SELECT cost FROM tbl_card tc WHERE tc.id = so.ticket_id )
END,
0
) cost
FROM
tbl_haiwei_coupon_order_relate r
INNER JOIN tbl_haiwei_coupon hc ON hc.id = r.coupon_id
INNER JOIN tbl_haiwei_coupon_batch cb ON hc.coupon_batch_id = cb.id
INNER JOIN tbl_agent a ON cb.agent_id = a.id
LEFT JOIN tbl_sell_order so ON so.id = r.order_id
AND r.order_type = 'SELL_ORDER'
LEFT JOIN tbl_recharge_order ro ON ro.id = r.order_id
AND r.order_type = 'RECHARGE_ORDER'
LEFT JOIN tbl_commodity commodity ON r.commodity_id = commodity.id
AND r.order_type = 'SELL_ORDER'
LEFT JOIN tbl_commodity_type ct ON commodity.commodity_type_id = ct.id
LEFT JOIN tbl_recharge_denomination rd ON r.commodity_id = rd.id
AND r.order_type = 'RECHARGE_ORDER'
LEFT JOIN tbl_recharge_commodity rc ON rd.commodity_id = rc.id
LEFT JOIN tbl_recharge_brand rb ON rc.brand_id = rb.id
ORDER BY
r.id DESC
使用left join 在on后使用两个条件,可以避免使用union或者多sql的情况。
慢Sql
对于复杂的大型sql,考虑拆分一些可能不走索引的条件,查出来id,并在业务层通过id对该字段重新组装。
Mybatis
一级缓存和二级缓存
一级缓存
Mybatis对缓存提供支持,但是在没有配置的默认情况下,它只开启一级缓存,一级缓存只是相对于同一个SqlSession而言。所以在参数和SQL完全一样的情况下,我们使用同一个SqlSession对象调用一个Mapper方法,往往只执行一次SQL,因为使用SelSession第一次查询后,MyBatis会将其放在缓存中,以后再查询的时候,如果没有声明需要刷新,并且缓存没有超时的情况下,SqlSession都会取出当前缓存的数据,而不会再次发送SQL到数据库。
- 但是,Mybatis认为不是同一个事务的查询请求不是同一个sqlSession,非同一事务的查询会创建一个新的sqlSession

为什么要使用一级缓存,不用多说也知道个大概。但是还有几个问题我们要注意一下。
1、一级缓存的生命周期有多长?
a、MyBatis在开启一个数据库会话时,会 创建一个新的SqlSession对象,SqlSession对象中会有一个新的Executor对象。Executor对象中持有一个新的PerpetualCache对象;当会话结束时,SqlSession对象及其内部的Executor对象还有PerpetualCache对象也一并释放掉。
b、如果SqlSession调用了close()方法,会释放掉一级缓存PerpetualCache对象,一级缓存将不可用。
c、如果SqlSession调用了clearCache(),会清空PerpetualCache对象中的数据,但是该对象仍可使用。
d、SqlSession中执行了任何一个update操作(update()、delete()、insert()) ,都会清空PerpetualCache对象的数据,但是该对象可以继续使用
2、怎么判断某两次查询是完全相同的查询?
mybatis认为,对于两次查询,如果以下条件都完全一样,那么就认为它们是完全相同的两次查询。
2.1 传入的statementId
2.2 查询时要求的结果集中的结果范围
2.3. 这次查询所产生的最终要传递给JDBC java.sql.Preparedstatement的Sql语句字符串(boundSql.getSql() )
2.4 传递给java.sql.Statement要设置的参数值
二级缓存:
MyBatis的二级缓存是Application级别的缓存,它可以提高对数据库查询的效率,以提高应用的性能。
MyBatis的缓存机制整体设计以及二级缓存的工作模式

SqlSessionFactory层面上的二级缓存默认是不开启的,二级缓存的开席需要进行配置,实现二级缓存的时候,MyBatis要求返回的POJO必须是可序列化的。 也就是要求实现Serializable接口,配置方法很简单,只需要在映射XML文件配置就可以开启缓存了
- 映射语句文件中的所有select语句将会被缓存。
- 映射语句文件中的所欲insert、update和delete语句会刷新缓存。
- 缓存会使用默认的Least Recently Used(LRU,最近最少使用的)算法来收回。
- 根据时间表,比如No Flush Interval,(CNFI没有刷新间隔),缓存不会以任何时间顺序来刷新。
- 缓存会存储列表集合或对象(无论查询方法返回什么)的1024个引用
- 缓存会被视为是read/write(可读/可写)的缓存,意味着对象检索不是共享的,而且可以安全的被调用者修改,不干扰其他调用者或线程所做的潜在修改。
实践:
一、创建一个POJO Bean并序列化
由于二级缓存的数据不一定都是存储到内存中,它的存储介质多种多样,所以需要给缓存的对象执行序列化。(如果存储在内存中的话,实测不序列化也可以的。)
package com.yihaomen.mybatis.model;
import com.yihaomen.mybatis.enums.Gender;
import java.io.Serializable;
import java.util.List;
/**
* @ProjectName: springmvc-mybatis
*/
public class Student implements Serializable{
private static final long serialVersionUID = 735655488285535299L;
private String id;
private String name;
private int age;
private Gender gender;
private List<Teacher> teachers;
setters&getters()....;
toString();
}
二、在映射文件中开启二级缓存
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.yihaomen.mybatis.dao.StudentMapper">
<!--开启本mapper的namespace下的二级缓存-->
<!--
eviction:代表的是缓存回收策略,目前MyBatis提供以下策略。
(1) LRU,最近最少使用的,一处最长时间不用的对象
(2) FIFO,先进先出,按对象进入缓存的顺序来移除他们
(3) SOFT,软引用,移除基于垃圾回收器状态和软引用规则的对象
(4) WEAK,弱引用,更积极的移除基于垃圾收集器状态和弱引用规则的对象。这里采用的是LRU,
移除最长时间不用的对形象
flushInterval:刷新间隔时间,单位为毫秒,这里配置的是100秒刷新,如果你不配置它,那么当
SQL被执行的时候才会去刷新缓存。
size:引用数目,一个正整数,代表缓存最多可以存储多少个对象,不宜设置过大。设置过大会导致内存溢出。
这里配置的是1024个对象
readOnly:只读,意味着缓存数据只能读取而不能修改,这样设置的好处是我们可以快速读取缓存,缺点是我们没有
办法修改缓存,他的默认值是false,不允许我们修改
-->
<cache eviction="LRU" flushInterval="100000" readOnly="true" size="1024"/>
<resultMap id="studentMap" type="Student">
<id property="id" column="id" />
<result property="name" column="name" />
<result property="age" column="age" />
<result property="gender" column="gender" typeHandler="org.apache.ibatis.type.EnumOrdinalTypeHandler" />
</resultMap>
<resultMap id="collectionMap" type="Student" extends="studentMap">
<collection property="teachers" ofType="Teacher">
<id property="id" column="teach_id" />
<result property="name" column="tname"/>
<result property="gender" column="tgender" typeHandler="org.apache.ibatis.type.EnumOrdinalTypeHandler"/>
<result property="subject" column="tsubject" typeHandler="org.apache.ibatis.type.EnumTypeHandler"/>
<result property="degree" column="tdegree" javaType="string" jdbcType="VARCHAR"/>
</collection>
</resultMap>
<select id="selectStudents" resultMap="collectionMap">
SELECT
s.id, s.name, s.gender, t.id teach_id, t.name tname, t.gender tgender, t.subject tsubject, t.degree tdegree
FROM
student s
LEFT JOIN
stu_teach_rel str
ON
s.id = str.stu_id
LEFT JOIN
teacher t
ON
t.id = str.teach_id
</select>
<!--可以通过设置useCache来规定这个sql是否开启缓存,ture是开启,false是关闭-->
<select id="selectAllStudents" resultMap="studentMap" useCache="true">
SELECT id, name, age FROM student
</select>
<!--刷新二级缓存
<select id="selectAllStudents" resultMap="studentMap" flushCache="true">
SELECT id, name, age FROM student
</select>
-->
</mapper>
三、在 mybatis-config.xml中开启二级缓存
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<settings>
<!--这个配置使全局的映射器(二级缓存)启用或禁用缓存-->
<setting name="cacheEnabled" value="true" />
.....
</settings>
....
</configuration>
四、测试
package com.yihaomen.service.student;
import com.yihaomen.mybatis.dao.StudentMapper;
import com.yihaomen.mybatis.model.Student;
import com.yihaomen.mybatis.model.Teacher;
import com.yihaomen.service.BaseTest;
import org.apache.ibatis.session.SqlSession;
import org.apache.ibatis.session.SqlSessionFactory;
import java.util.List;
/**
*
* @ProjectName: springmvc-mybatis
*/
public class TestStudent extends BaseTest {
public static void selectAllStudent() {
SqlSessionFactory sqlSessionFactory = getSession();
SqlSession session = sqlSessionFactory.openSession();
StudentMapper mapper = session.getMapper(StudentMapper.class);
List<Student> list = mapper.selectAllStudents();
System.out.println(list);
System.out.println("第二次执行");
List<Student> list2 = mapper.selectAllStudents();
System.out.println(list2);
session.commit();
System.out.println("二级缓存观测点");
SqlSession session2 = sqlSessionFactory.openSession();
StudentMapper mapper2 = session2.getMapper(StudentMapper.class);
List<Student> list3 = mapper2.selectAllStudents();
System.out.println(list3);
System.out.println("第二次执行");
List<Student> list4 = mapper2.selectAllStudents();
System.out.println(list4);
session2.commit();
}
public static void main(String[] args) {
selectAllStudent();
}
}
结果:
[QC] DEBUG [main] org.apache.ibatis.transaction.jdbc.JdbcTransaction.setDesiredAutoCommit(98) | Setting autocommit to false on JDBC Connection [com.mysql.jdbc.JDBC4Connection@51e0173d]
[QC] DEBUG [main] org.apache.ibatis.logging.jdbc.BaseJdbcLogger.debug(139) | ==> Preparing: SELECT id, name, age FROM student
[QC] DEBUG [main] org.apache.ibatis.logging.jdbc.BaseJdbcLogger.debug(139) | ==> Parameters:
[QC] DEBUG [main] org.apache.ibatis.logging.jdbc.BaseJdbcLogger.debug(139) | <== Total: 6
[Student{id='1', name='刘德华', age=55, gender=null, teachers=null}, Student{id='2', name='张惠妹', age=49, gender=null, teachers=null}, Student{id='3', name='谢霆锋', age=35, gender=null, teachers=null}, Student{id='4', name='王菲', age=47, gender=null, teachers=null}, Student{id='5', name='汪峰', age=48, gender=null, teachers=null}, Student{id='6', name='章子怡', age=36, gender=null, teachers=null}]
第二次执行
[QC] DEBUG [main] org.apache.ibatis.cache.decorators.LoggingCache.getObject(62) | Cache Hit Ratio [com.yihaomen.mybatis.dao.StudentMapper]: 0.0
[Student{id='1', name='刘德华', age=55, gender=null, teachers=null}, Student{id='2', name='张惠妹', age=49, gender=null, teachers=null}, Student{id='3', name='谢霆锋', age=35, gender=null, teachers=null}, Student{id='4', name='王菲', age=47, gender=null, teachers=null}, Student{id='5', name='汪峰', age=48, gender=null, teachers=null}, Student{id='6', name='章子怡', age=36, gender=null, teachers=null}]
二级缓存观测点
[QC] DEBUG [main] org.apache.ibatis.cache.decorators.LoggingCache.getObject(62) | Cache Hit Ratio [com.yihaomen.mybatis.dao.StudentMapper]: 0.3333333333333333
[Student{id='1', name='刘德华', age=55, gender=null, teachers=null}, Student{id='2', name='张惠妹', age=49, gender=null, teachers=null}, Student{id='3', name='谢霆锋', age=35, gender=null, teachers=null}, Student{id='4', name='王菲', age=47, gender=null, teachers=null}, Student{id='5', name='汪峰', age=48, gender=null, teachers=null}, Student{id='6', name='章子怡', age=36, gender=null, teachers=null}]
第二次执行
[QC] DEBUG [main] org.apache.ibatis.cache.decorators.LoggingCache.getObject(62) | Cache Hit Ratio [com.yihaomen.mybatis.dao.StudentMapper]: 0.5
[Student{id='1', name='刘德华', age=55, gender=null, teachers=null}, Student{id='2', name='张惠妹', age=49, gender=null, teachers=null}, Student{id='3', name='谢霆锋', age=35, gender=null, teachers=null}, Student{id='4', name='王菲', age=47, gender=null, teachers=null}, Student{id='5', name='汪峰', age=48, gender=null, teachers=null}, Student{id='6', name='章子怡', age=36, gender=null, teachers=null}]
Process finished with exit code 0
我们可以从结果看到,sql只执行了一次,证明我们的二级缓存生效了。
二级缓存注解方式的使用
MyBatis @Options使用方法
MyBatis的@Options注解能够设置缓存时间,能够为对象生成自增的主键值,一般应用于两种场景
-
查询时
@SelectProvider(type=xxx.clsss,method="xxxmethod")
@Options(useCache=true,flushCache=Options.FlushCachePolicy.FALSE, timeout= 1000)
userCache是否使用缓存,flushCache刷新缓存策略这里表示查询不刷新缓存,timeout表示查询结果缓存1000秒
-
插入时
@Options(useGeneratedKeys=true, keyProperty="xxxId", keyColumn="xxxId",flushCache=Options.FlushCachePolicy.FALSE)
设置@Options属性userGeneratedKeys的值为true,并指定实例对象中主键的属性名keyProperty以及在数据库中的字段名keyColumn。这样在gendar插入数据后,gendarId属性会被自动赋值。
当然flushCache 仍然可以设置,表示插入数据后是否更新缓存,默认是true。、
整个命名空间的注解
@CacheNamespace(flushInterval = 3 * 1000)
级联查询
要实现级联查询必须以内嵌对象的方式进行关联,而不能仅关联主键,仅关联主键是无法做到级联查询的,但我们在开发中往往采用的就是仅关联主键,也就是说级联查询在开发中其实用到的并不多。
Redis
- 对于连续执行的多redis命令,可以用redisTemplate的管道
redis是一个高性能的单线程的key-value数据库。它的执行过程为:
(1)发送命令-〉(2)命令排队-〉(3)命令执行-〉(4)返回结果
如果我们使用redis进行批量插入数据,正常情况下相当于将以上四个步骤批量执行N次。(1)和(4)称为Round Trip Time(RTT,往返时间)。在一条简单指令中,往往(1)(4)步骤之和大过于(2)(3)步骤之和,如何进行优化?Redis提供了pipeline管道机制,它能将一组Redis命令进行组装,通过一次RTT传输给Redis,并将这组Redis命令的执行结果按顺序返回给客户端。
public class RedisUtil {
@Autowired
private RedisTemplate redisTemplate;
/**
* 功能描述: 使用pipelined批量存储
*
* @param: [map, seconds]
* @return: void
* @auther: liyiyu
* @date: 2020/4/19 14:34
*/
public void executePipelined(Map map, long seconds) {
RedisSerializer serializer = redisTemplate.getStringSerializer();
redisTemplate.executePipelined(new RedisCallback() {
@Override
public String doInRedis(RedisConnection connection) throws DataAccessException {
map.forEach((key, value) -> {
connection.set(serializer.serialize(key), serializer.serialize(value),Expiration.seconds(seconds), RedisStringCommands.SetOption.UPSERT);
});
return null;
}
},serializer);
}
}
SpringMVC
解析文章:https://blog.csdn.net/qq_38975553/article/details/103709984
核心入口类: DispatcherServlet
响应处理JSON
springmvc处理json: https://www.cnblogs.com/hujingwei/p/5351378.html
使用HttpMessageConverter
-
使用@RequestBody/@ResponseBody
-
使用HttpEntity
/ResponseEntity 作为方法的入参或返回值。
当处理方法使用到@RequestBody/@ResponseBody或HttpEntity
ContentNegotiatingViewResolver ,“内容协商视图解析器”,其实就是根据返回什么类型的视图,就协商使用哪种视图解析器。如果返回jsp就使用InternalResourceViewResolver视图解析器,如果返回JSON格式就使用MappingJackson2JsonView来处理。
返回jsp或thymleaf视图时会找到静态页面地址,然后处理绑定对象, 将内容放到响应体中一起返回.如果是json视图, 则只会返回被序列化为JSON的对象作为响应体.
注: Spring在请求进行的各个生命周期都有钩子, 可以通过实现或继承或用@Bean重写的方式来扩展增强.
抛出异常时两次分发请求的问题
-
问题: 需求是增加一个切面,用来对所有ModelAndView的页面增加一个地址字段。但所有的抛出异常的返回json格式的数据会被拼接了两份json
-
原因:
-
切入点范围过大;切入点为@Pointcut("execution(org.springframework.web.servlet.ModelAndView *(..))"),导致所有返回ModelAndView的方法都会被切入, 而SpringMvc的handler核心处理方法会返回ModelAndView,正好被切入到了。(如果controller方法里抛出了异常会被HandlerExceptionResolverComposite.resolveException()中的ModelAndView mav = handlerExceptionResolver.resolveException(request, response, handler, ex); 处理, 也会被切入)
@Pointcut("execution(org.springframework.web.servlet.ModelAndView *(..))") public void basePathPageReturn() {} @AfterReturning(value = "basePathPageReturn()", returning = "returnValue") public void pageReturn(ModelAndView returnValue) { if (returnValue != null) { returnValue.addObject("basePath", "我是一个页面"); } } -
抛出异常生成的mv被切面切入;在DispatcherServlet.processHandlerException方法中,首先根据异常解析器返回一个mv, 返回的mv数据为:ModelAndView [view = [null]; model=[null]], 会被切面切入,model被强行塞入了个object数据。在接下来判断是否是一个可渲染的视图时,本应该返回null的mv作为一个视图继续往下执行了。
if (exMv != null) { if (exMv.isEmpty()) { request.setAttribute(EXCEPTION_ATTRIBUTE, ex); return null; } -
渲染视图时本获取输出流已经被抛出的异常又被获取一次流,报【IllegalStateException: getOutputStream() has already been called for this response】
final Writer templateWriter = (producePartialOutputWhileProcessing? response.getWriter() : new FastStringWriter(1024)); -
请求转发至error视图时由于原请求是json序列化形式数据,所以会被HttpMessageConverter转化成json格式,同时被响应体增强钩子获取,生成新的MessageBean,并被拼接成两个json形式数据输出。
@Override public Object beforeBodyWrite(Object body, MethodParameter methodParameter, MediaType mediaType, Class aClass, ServerHttpRequest request, ServerHttpResponse serverHttpResponse) { if (body instanceof SimpleMessage || body instanceof MessageBean) { return body; } MessageBean result = new MessageBean(); result.setErrorCode(ResponseCodeEnum.OK.getCode()); result.setErrorMsg("OK"); result.setData(body); body = result; return body; }
限制切面不切springmvc的源码中的方法。@Pointcut("execution(public org.springframework.web.servlet.ModelAndView cn.decentchina.coolcard.customize...(..))")
右移一位, 然后|原来。
-
JDK源码
阅读笔记简版
1、Object
- wait(), notify(), notifyAll(), wait(timeout) 是本地c++的方法
- hashCode() 本地方法, equals() 判断地址是否相同
- clone() 本地的浅拷贝方法,如果没有实现Cloneable就调用该方法,则抛出CloneNotSuppootedException
2、String
- char[] value
- int hash
- equals(), startWith(), endWith(), replace
3、AbstractStringBuilder
- char[] value
- int count
- 扩容:*2+1, 不够则取所需最小的,超过Integer的限制则只取Integer最大值
//minimumCapacity是所需最小的容量
void expandCapacity(int minimumCapacity) {
int newCapacity = value.length * 2 + 2;
if (newCapacity - minimumCapacity < 0)
newCapacity = minimumCapacity;
if (newCapacity < 0) {
if (minimumCapacity < 0) // overflow
throw new OutOfMemoryError();
newCapacity = Integer.MAX_VALUE;
}
value = Arrays.copyOf(value, newCapacity);
}
4、StringBuffer
- 继承AbstractStringBuilder
- synchronized方法保证线程安全, 在所有可能导致同步错误的方法上加上synchronized
- char[] toStringCache
//当StringBuffer中value值有任何更新时,缓存字段设为null
public synchronized String toString() {
if (toStringCache == null) {
toStringCache = Arrays.copyOfRange(value, 0, count);
}
return new String(toStringCache, true);
}
//使用这个共享数组构造器,直接赋值,而没有带这个share则是需要Array.copyOf()来创建一个副本,所以速度会快一些
String(char[] value, boolean share) {
// assert share : "unshared not supported";
this.value = value;
}
//传入字符串的初始化时,会建立16+字符串长度的容量
public StringBuffer(String str) {
super(str.length() + 16);
append(str);
}
5、StringBuilder 继承AbstractStringBuilder
public String toString() {
return new String(value, 0, count);
}
6、ArrayList
- Object[] elementData 存储ArrayList的元素的数组缓冲区。 ArrayList的容量是此数组缓冲区的长度。 添加第一个元素时,任何具有elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA(默认空数组{})的空ArrayList都将扩展为DEFAULT_CAPACITY。
- int size
- 默认大小10
- 扩容:1.5倍,不够取所需最小
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
7、LinkedList
- Node {E item, Node prev, Node next} 双向链表
- int size
- Node first
- Node last
- linkFirst() 链接作为头, linkLast()链接作为尾部, linkBefore()插入结点在当前结点之前, unLinkFirst()取消链接头结点, unLinkLast()取消链接尾结点, unLink()取消链接非空结点, indexOf()找到第一个出现位置
8、HashTable:
9、HashSet:委托给HashMap(对象中维护一个HashMap,使用其键),其Value是同一个默认对象
private static final Object PRESENT = new Object();
10、LinkedHashSet继承HashSet:不知道如何实现的顺序?
11、AbstractMap维护EntrySet,AbstractSet维护Iterator,AbstractList维护Iterator
12、TreeSet:委托TreeMap实现
HashMap
-
threshold是负载因子*容量的值,是扩容的阈值,当size(HashMap中所有的数据个数)超过阈值时, put中会触发resize()
-
resize()
-
扩容时,如果旧数组中已有数据,会通过下面的取余操作来判断当前的hashcode是否超过了旧容量的大小,如果超过了会重新移动位置。那么为什么要对一个bin中的每一个元素都要进行判断呢?因为比如对于bin 4,在容量为8的情况下,hashCode为4和12都会进入到这个位置,而扩容后就不一定了。
-
单个桶链表超过8,且当前数组已有值大小超过64,才会转为红黑树,否则进行扩容一次。
-
//当所有map中所有数据个数大于阈值,那么就进行扩容,这样可以对里面所有数据进行重新hash,重新排版。 if (++size > threshold) resize();
-
-
保证扩容时以2的次幂
或| 的特点是,只要有1,不断或,那么1不会消失,连续或2的0-4次幂,保证以当前传入参数的第一位1开始 后面都填满1
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
- 使用-1与操作取余, 因为n代表容量, 而容量一定是2的次幂,-1后二进制一定是全是1, 这样对当前值的hashcode进行与操作时, hashcode多与容量的位数会全部截取, 剩下的就是余数。
(n - 1) & hash
HashMap如何有效减少碰撞
1、扰动函数算法,促使元素位置分布均匀,减少碰撞几率;
2、使用final对象,并采用合适的equals方法和hashCode方法;
LinkedHashMap
-
LinkedHashMap是HashMap的子类,内部使用双链表进行顺序的维护,内部类Entry为HashMap的Node的子类
-
三参数构造器,如果accessOrder为true,那么表示将顺序记录为访问顺序,否则为插入顺序,默认为false。因为这个参数并可以对removeEldestEntry方法进行覆盖便可以实现一个简单的LRU缓存(在afterNodeInsertion方法中,如果覆盖了该方法,可以对符合条件的结点移除)。https://www.cnblogs.com/wyq178/p/9976815.html

-
put操作其实和父类HashMap采用相同的实现,在HashMap部分也提到了afterNodeAccess(访问一次就调用,用来交换当前结点和尾结点位置来实现lru)和afterNodeInsertion方法其实是空实现,而在LinkedHashMap中对其进行了实现,Linked的特性也是在这里进行了体现。(因为是继承的HashMap,所以只需要将空方法覆盖掉)
-
与HashMap相比,LinkedHashMap由于在插入是需要进行额外的双链表链接工作,所以在插入性能上必定不如HashMap,但在遍历时,LinkedHashMap的性能反而更高,因为只需遍历链表即可(因为维护了头结点和尾结点,并根据构造方法维护了顺序),而HashMap需要遍历bin和链表(或红黑树)。
TreeMap
- 与HashMap不同, 其维护了一个红黑树。
- TreeMap继承自SortedMap,使用
TreeMap时,放入的Key必须实现Comparable接口。String、Integer这些类已经实现了Comparable接口,因此可以直接作为Key使用。作为Value的对象则没有任何要求。如果作为Key的class没有实现Comparable接口,那么,必须在创建TreeMap时同时指定一个自定义排序算法
ConcurrentHashMap
-
locked变量不再是boolean类型而是AtomicBoolean。这个类中有一个compareAndSet()方法,它使用一个期望值和AtomicBoolean实例的值比较,和两者相等,则使用一个新值替换原来的值。在以下代码里,它比较locked的值和false,如果locked的值为false,则把修改为true。如果值被替换了,compareAndSet()返回true,否则,返回false。使用Java提供的CAS特性而不是使用自己实现的的好处是Java中内置的CAS特性可以让你利用底层的你的程序所运行机器的CPU的CAS特性。这会使还有CAS的代码运行更快。以下是使用CAS简单实现的自旋锁 https://www.cnblogs.com/coding-night/p/10818065.html
-
public static MyLock lock = new MyLock(); public static Integer count = 1; public static CountDownLatch countDownLatch = new CountDownLatch(1000000); public static ExecutorService testPool = new ThreadPoolExecutor(2, 5, 60, TimeUnit.SECONDS, new LinkedBlockingQueue<>(), new ThreadPoolExecutor.AbortPolicy()); public static class MyLock { private AtomicBoolean locked = new AtomicBoolean(false); public boolean lock() { return locked.compareAndSet(false, true); } } static Boolean flag = true; static class Task implements Runnable { @Override public void run() { while (true) { if (lock.lock()) { // flag = false; count++; lock.locked = new AtomicBoolean(false); countDownLatch.countDown(); // flag = true; return; } else { //线程从执行变为就绪,而不是挂起 Thread.yield(); } } } } @Test public void test() throws InterruptedException { Date now = new Date(); for(int i = 0; i<1000000; i++) { testPool.submit(new Task()); } testPool.shutdown(); Date end = new Date(); countDownLatch.await(); System.out.println(count); System.out.println(end.getTime()-now.getTime()); }
获取Unsafe的方法
public static Unsafe getUnsafe() {
try {
Field f = Unsafe.class.getDeclaredField("theUnsafe");
f.setAccessible(true);
return (Unsafe)f.get(null);
} catch (Exception e) {
return null;
}
-
putVal(K key, V value, boolean onlyIfAbsent)方法干的工作如下:
1、检查key/value是否为空,如果为空,则抛异常,否则进行2
2、进入for死循环,进行3
3、检查table是否初始化了,如果没有,则调用initTable()进行初始化然后进行 2,否则进行4
4、根据key的hash值计算出其应该在table中储存的位置i,取出table[i]的节点用f表示。
根据f的不同有如下三种情况: 1)如果table[i]==null(即该位置的节点为空,没有发生碰撞),则利用CAS操作直接存储在该位置,如果CAS操作成功则退出死循环。
2)如果table[i]!=null(即该位置已经有其它节点,发生碰撞),碰撞处理也有两种情况
2.1)检查table[i]的节点的hash是否等于MOVED,如果等于,则检测到正在扩容,则帮助其扩容
2.2)说明table[i]的节点的hash值不等于MOVED,如果table[i]为链表节点,则将此节点插入链表中即可, 如果table[i]为树节点,则将此节点插入树中即可。插入成功后,进行 5
5、如果table[i]的节点是链表节点,则检查table的第i个位置的链表是否需要转化为树,如果需要则调用treeifyBin函数进行转化 1)第一步根据给定的key的hash值找到其在table中的位置index。
2)找到位置index后,存储进行就好了。
这里的存储有三种情况
第一种:table[index]中没有任何其他元素,即此元素没有发生碰撞,这种情况直接存储就好了哈。
第二种,table[i]存储的是一个链表,如果链表不存在key则直接加入到链表尾部即可,如果存在key则更新其对应的value。
第三种,table[i]存储的是一个树,则按照树添加节点的方法添加就好。final V putVal(K key, V value, boolean onlyIfAbsent) { if (key == null || value == null) throw new NullPointerException(); //计算hash值,两次hash操作int binCount = 0; int hash = spread(key.hashCode()); int binCount = 0; //类似于while(true),死循环,直到插入成功 for (Node<K,V>[] tab = table;;) { Node<K,V> f; int n, i, fh; //检查是否初始化了,如果没有,则初始化 if (tab == null || (n = tab.length) == 0) tab = initTable(); //i=(n-1)&hash 等价于i=hash%n(前提是n为2的幂次方).即取出table中位置的节点用f表示。 //有如下两种情况: //1.如果table[i]==null(即该位置的节点为空,没有发生碰撞),则利用CAS操作直接存储在该位置,如果CAS操作成功则退出死循环。 else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) { if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value, null))) break; // no lock when adding to empty bin } //检查table[i]的节点的hash是否等于MOVED,如果等于,则检测到正在扩容, else if ((fh = f.hash) == MOVED) //帮助其扩容 tab = helpTransfer(tab, f); //运行到这里,说明table[i]的节点的hash值不等于MOVED else { V oldVal = null; //锁定,(hash值相同的链表的头节点) synchronized (f) { //避免多线程,需要重新检查 if (tabAt(tab, i) == f) { //链表节点 if (fh >= 0) { binCount = 1; //下面的代码就是先查找链表中是否出现了此key,如果出现,则更新value,并跳出循环, //否则将节点加入到列表末尾并跳出循环 for (Node<K,V> e = f;; ++binCount) { K ek; if (e.hash == hash && ((ek = e.key) == key || (ek != null && key.equals(ek)))) { oldVal = e.val; //仅putIfAbsent()方法中onlyIfAbsent为true if (!onlyIfAbsent) e.val = value; break; } Node<K,V> pred = e; //插入到链表末尾并跳出循环 if ((e = e.next) == null) { pred.next = new Node<K,V>(hash, key, value, null); break; } } } //如果是一个树节点, else if (f instanceof TreeBin) { Node<K,V> p; binCount = 2; //插入到树中 if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key, value)) != null) { oldVal = p.val; if (!onlyIfAbsent) p.val = value; } } } } if (binCount != 0) { // 插入成功后,如果插入的是链表节点,则要判断下该桶位是否要转化为树if (binCount != 0) { // 实则是 > 8,执行else,说明该桶位本就有Node if (binCount >= TREEIFY_THRESHOLD) //若length<64,直接tryPresize,两倍table.length;不转树 if (oldVal != null) //这里是为了避免table 过小的时候就进行转换成树的。 treeifyBin(tab, i); if (oldVal != null) return oldVal; break; } } } addCount(1L, binCount); return null; } -
helpTransfer() 分析
补码
我们都知道负数在计算机中是以补码(忘了补码定义的戳这里)表示的,那为什么呢?本文尝试了解补码的原理,而要想理解它,首先得理解算术中“模”的概念。所以首先看一下什么是模,然后通过一个小例子来理解补码。
1 模(Modulo)
1.1 什么是模数
In mathematics, modular arithmetic is a system of arithmetic for integers, where numbers “wrap around” upon reaching a certain value—the modulus (plural moduli).
1.1.1 理解
模是指一个计量系统的计数范围。如时钟等。计算机也是一个计算器,它也是有一个计量范围,即都存在一个“模”。
如时钟的计量范围是0~11,模 = 12。
32位计算机的计量范围是232,模 = 232。
“模”是计量器产生“溢出”的量,它的值在计量器上表示不出来,计量器上只能表示出模的余数,如12的余数有0,1,2,3,4,5,6,7,8,9,10,11。
1.2 补数
假设当前时针指向11点,而准确时间是8点,调整时间可有以下两种拨法:
一种是倒拨3小时,即:11-3=8
另一种是顺拨9小时:11+9=12+8=8
在以模为12的系统中,加9和减3效果是一样的,因此凡是减3运算,都可以用加9来代替。对“模”12而言,9和3互为补数(二者相加等于模)。所以我们可以得出一个结论,即在有模的计量系统中,减一个数等于加上它的补数,从而实现将减法运算转化为加法运算的目的。
1.3 再谈“模”
从上面的化减法为加法,以及所谓的溢出等等可以看到,“模”可以说就是一个太极,阴阳转化,周而复始,无始无终,循环往复。
2 补码原理
计算机上的补码就是算术里的补数。
设我们有一个 4 位的计算机,则其计量范围即模是
2^4 = 16,所以其能够表示的范围是0~15,现在以计算 5 - 3为例,我们知道在计算机中,加法器实现最简单,所以很多运算最终都要转为加法运算,因此5-3就要转化为加法:
# 按以上理论,减一个数等于加上它的补数,所以
5 - 3
# 等价于
5 + (16 - 3) // 算术运算单元将减法转化为加法
# 用二进制表示则为:
0101 + (10000 - 0011)
# 等价于
0101 + ((1 + 1111) - 0011)
# 等价于
0101 + (1 + (1111 - 0011))
# 等价于
0101 + (1 + 1100) // 括号内是3(0011)的反码+1,正是补码的定义
# 等价于
0101 + 1101
# 所以从这里可以得到
-3 = 1101
# 即 -3 在计算机中的二进制表示为 1101,正是“ -3 的正值 3(0011)的补码(1101)”。
# 最后一步 0101 + 1101 等于
10010
因为我们的计算机是 4 位的,第一位“溢出”了,所以我们只保存了 4 位,即 0010,而当计算机去读取时这正是我们所期望的 2
内部锁
CAS基于乐观锁实现,synchronized是基于悲观锁的,当一个线程试图访问同步代码块时,它首先必须得到锁,退出或抛出异常时必须释放锁。
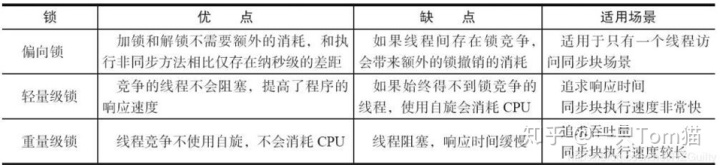
偏向锁
当一个线程访问同步块并获取锁时,会在对象头和栈帧中的锁记录里存储锁偏向的线程ID,以后该线程在进入和退出同步块时不需要进行CAS操作来加锁和解锁,只需简单地测试一下对象头的Mark Word里是否存储着指向当前线程的偏向锁。如果测试成功,表示线程已经获得了锁。如果测试失败,则需要再测试一下Mark Word中偏向锁的标识是否设置成1(表示当前是偏向锁),如果没有设置,则使用CAS竞争锁;如果设置了,则尝试使用CAS将对象头的偏向锁指向当前线程。
轻量级锁
线程在执行同步块之前,JVM会先在当前线程的栈桢中创建用于存储锁记录的空间,并将对象头中的Mark Word复制到锁记录中。然后线程尝试使用CAS将对象头中的Mark Word替换为指向锁记录的指针。如果成功,当前线程获得锁,如果失败,表示其他线程竞争锁,当前线程便尝试使用自旋来获取锁。(这里的自旋可以通过jvm参数配置来控制重试次数,以及可以使用自适应自旋锁)
重量级锁
重量级锁是依赖对象内部的monitor锁来实现。当系统检查到锁是重量级锁之后,会把等待想要获得锁的线程进行阻塞,被阻塞的线程不会消耗cup。但是阻塞或者唤醒一个线程时,都需要操作系统来帮忙,需要从用户态转换到内核态,而转换状态是需要消耗很多时间。
AQS:
https://www.cnblogs.com/fsmly/p/11274572.html
当手机浏览器和PC浏览器响应不一致时的调试方法
- 利用Fiddler自带的代理服务器,使得手机发送的请求可以通过Fiddler中转,达到对手机浏览器抓包的效果
- 打开fiddler后,在在options中设置代理端口,以及开启选项
- 手机连接与pc同一个wifi,并将ip和端口号设置为fiddler代理服务器
- 手机下载Thor, Anubis, Shu, 通过软件VPN的方式抓包
枚举打印值
enum` `AccountType
{
``SAVING, FIXED, CURRENT;
``private` `AccountType()
``{
``System.out.println(“It is a account type”);
``}
}
class` `EnumOne
{
``public` `static` `void` `main(String[]args)
``{
``System.out.println(AccountType.FIXED);
``}
}
枚举类在后台实现时,实际上是转化为一个继承了java.lang.Enum类的实体类,原先的枚举类型变成对应的实体类型,上例中AccountType变成了个class AccountType,并且会生成一个新的构造函数,若原来有构造函数,则在此基础上添加两个参数,生成新的构造函数,如上例子中:
private` `AccountType(){ System.out.println(“It is a account type”); }
会变成:
private` `AccountType(String s, ``int` `i){`` ``super``(s,i); System.out.println(“It is a account type”); }
而在这个类中,会添加若干字段来代表具体的枚举类型:
public` `static` `final` `AccountType SAVING;``public` `static` `final` `AccountType FIXED;``public` `static` `final` `AccountType CURRENT;
而且还会添加一段static代码段:
static``{`` ``SAVING = ``new` `AccountType(``"SAVING"``, ``0``);`` ``... CURRENT = ``new` `AccountType(``"CURRENT"``, ``0``);`` ``$VALUES = ``new` `AccountType[]{`` ``SAVING, FIXED, CURRENT`` ``} }
以此来初始化枚举中的每个具体类型。(并将所有具体类型放到一个$VALUE数组中,以便用序号访问具体类型)
在初始化过程中new AccountType构造函数被调用了三次,所以Enum中定义的构造函数中的打印代码被执行了3遍。