
我对服务端分片的理解是:1)具体数据片数如何实现;2)服务端的数据的存储、迁移;3)数据分片的高可用等对客户端来说就是透明无感的。
区别于Redis Sharding这种轻量方案,Cluster是Redis官方于Redis 3.0发布后推出的一种服务端分片的解决方案,它解决了多Redis实例下的协同问题。这里的协同包含数据自动分片、不同哈希槽(slot)的故障自动转移、节点扩缩容等功能。你看,数据分片以前是靠客户端自己解决的,哈希槽故障自动转移以前是靠额外的哨兵机制解决的,现在官方搞个整体解决方案以帮助客户端轻量化以便客户端能够更聚焦于业务逻辑的开发工作。
基本原理
首先,Redis Cluster采用的是基于P2P的 去中心化网络拓扑架构,没有中心节点,所有节点通过Gossip协议通信,所有节点既是数据存储节点,也是控制节点。
接着,它放弃了一致性哈希算法,取而代之引入槽(slot)的这样一个概念,通过CRC+hashslot这种哈希算法支持多个主节点(分片),每个主节点分别负责存储一部分数据,这样理论上可以支持无限主节点的 水平扩容以便支持海量吞吐量(实际上作者建议最好不超过1000个节点)。
另外,内置类似哨兵(Sentinal) 高可用机制,能够实现自动故障转移,保证每个主节点(分片)的高可用。
网络拓扑:
集群中的每个节点都是平等的(因为每个节点都知道整个集群其他节点的信息,如IP、端口、状态等,每个节点间都是相互通过Gossip协议通讯的),跟那些比特币的那些是不是有点类似呢?它跟哨兵模式(Sentinel)的本质上差异也在于这里,一个去中心化网络,一个还是分布式的主从模式。
这里我画个概念图方便大家理解他们的区别吧。其中哨兵模式更多是分布式网络,Gossip协议更多是去中心化网络。前几年比较火的比特币实际上也是用这种P2P协议进行交易和区块信息扩散的。
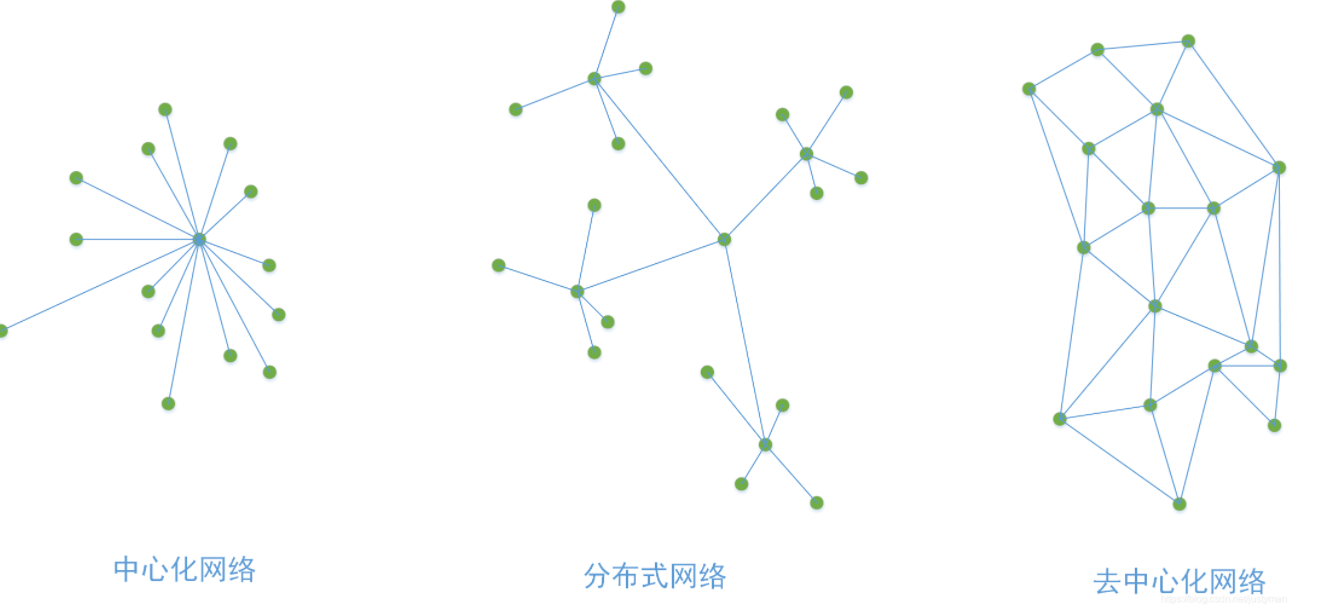
通信协议:
首先这里的通信协议指的是每个节点间的通信,节点间用的是Gossip协议。
Gossip协议起源于流行病学的研究,一般叫法是流言算法,也叫流行病协议。最初是在1987年发表在ACM上 的论文《Epidemic Algorithms for Replicated Database Maintenance》中,当时主要用在分布式数据库系统中各个副本节点间同步数据。具体Gossip协议可以在ACM上面获取。但这里可以大致说一下它的一些特性:
容错性
Gossip天然是容错的,每个节点既是通信主节点又是通信从节点,网络中每个节点的加入退出都会被相邻节点发现并同步扩散到其他节点,这从另外一个侧面也说明了该网络作为一个整体的整体健壮性。另外,该协议天然对网络质量没有严格要求,因此很多的算法实现基本上是基于UDP,因此从网络层容错来说也算是逻辑自洽。
一致性收敛
这个主要从信息同步的速度来讲的。假设网络中有N个节点,那信息同步到全网络的速度理论上仅需为O(log(N))次(具体每个节点一次同步的节点数由fanout参数决定)。还记得高数吗?这种对数函数的收敛速度是很快的。
当然,因为它只负责发送而不负责接收确认ACK,也因此存在一定的传播冗余度和非强一致性,但是却能保证最终一致性,我认为它更应该叫具备冗余特性的最终一致性算法。
去中心化
实际上Gossip协议还是基于一种叫SWIM的可扩展的弱一致性具备传染特性的进程组成员协议( S calable W eakly-consistent I nfection-style Process Group M embership Protocol)。各个节点通过push、pull或push/pull等方式进行节点信息同步以致整个网络达成统一,中间过程不存在所谓的中心节点。
Redis Cluster上下文的Gossip通信:
上面也简单说了一下具体协议,下面开始介绍一下节点如何使用该协议通信吧。一般来说,Cluster模式下每个节点都需要开通两个端口。
一个就是常规6379端口的,用于提供数据的读写服务;
另外一个用于做节点状态信息交互,端口一般是(6379+ 10000),这个就是所谓的Cluster bus,实际上就是它使用Gossip协议进行节点通信的啦。
自动数据分片
首先,这里指的“自动”是相对客户端而言的,数据的分片存储不需要像Redis Sharding需要客户端自己实现。
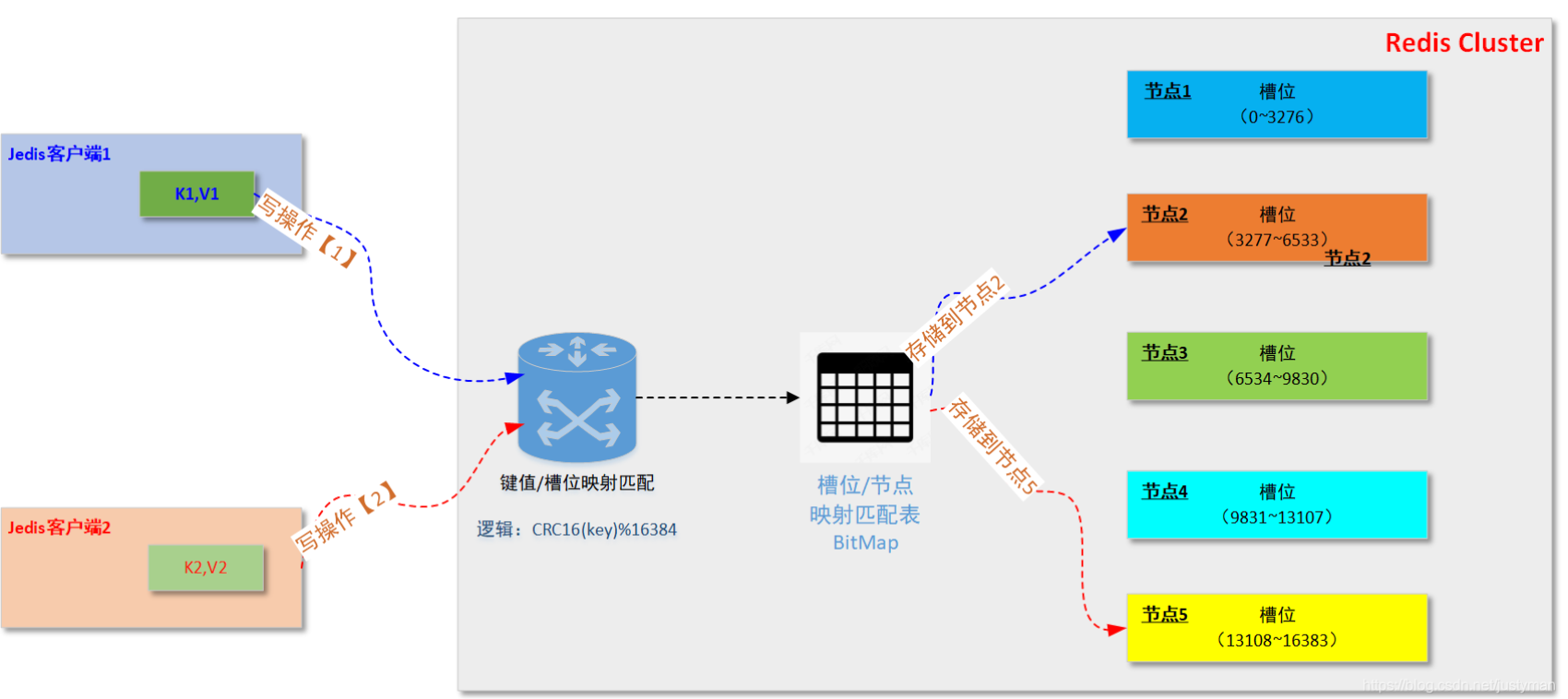
接着,“数据分片”,从下面的概念图可以看出来,Cluster内部的数据分片总共分为16384个槽,然后每个Redis节点负责管理一部分槽的读写操作。然后,具体每个键值对存储在哪个槽主要取决于 CRC16(key)%16384的这个值。其中CRC16是循环冗余码校验算法,这个我们应该不陌生,这个winrar里面使用的CRC32是一样的,只是校验长度不一样而已。
如下图,当客户端发起一个写操作的时候,该操作到达服务端后会通过一个CRC16(KEY)%16384的逻辑进行槽位匹配,接着通过存储在每个物理节点内存中的槽位/节点映射表(一般通过bitmap实现)进行匹配,最后把该键值对写到对应的节点上的某个槽位中,整个过程对于客户端来说是透明的。
另外,这里还要细化一个细节。当客户端连接集群中任一Redis节点并发送读写操作时,如果该实例收到的请求经过CRC计算后发现不属于自己负责的槽位时,会将请求的所属的节点及槽位信息返回给客户端,客户端接着自动将原请求重新发往这个地址,整个过程对外部透明,具体逻辑可以参考以下这个图。
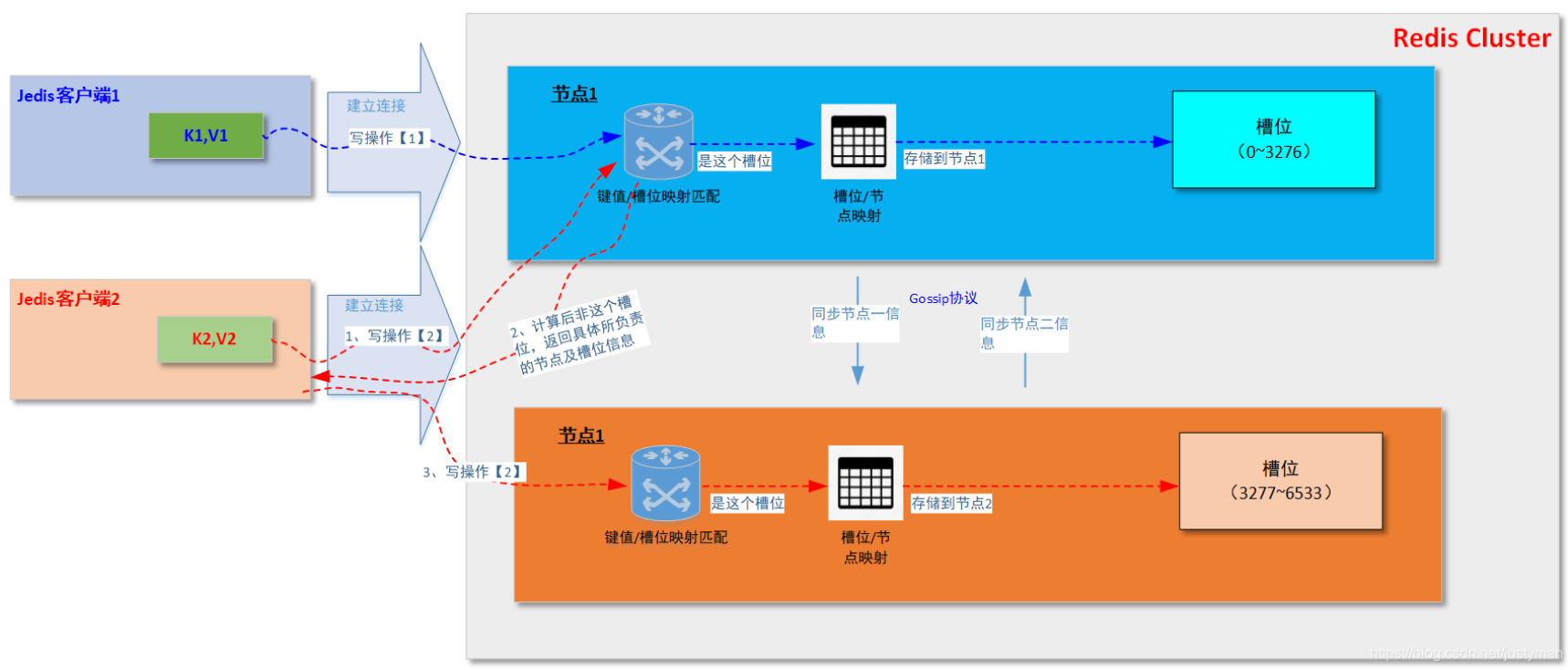
实际上上面第二个图会涉及到重定向的问题,如果每次都这样的话意味着网络开销还是蛮大的,因此就出现了Smart Jedis这种“聪明的”客户端。它机制是这样的:
每次在客户端在初始化的时候在本地会创建一个【槽位/节点映射表】,且客户端一般已经提供CRC16的算法实现(如JedisCluster里面的JedisClusterCRC16.getCRC16),然后当有请求进来时在本地先计算槽位,然后在表中找出对应节点,然后就可以直接访问对应节点并进行读写操作,而免去了根据错误节点返回的Move指令进行重定向;
如果真的发生数据迁移而返回Move指令的话,具体的重定向还是会继续,但是客户端会同步根据Move指令返回的节点信息更新到【槽位/节点映射表】,一来二去基本很快就可以更新完该表,然后后续的请求就能够直接通过该表进行节点定位,提升效率。
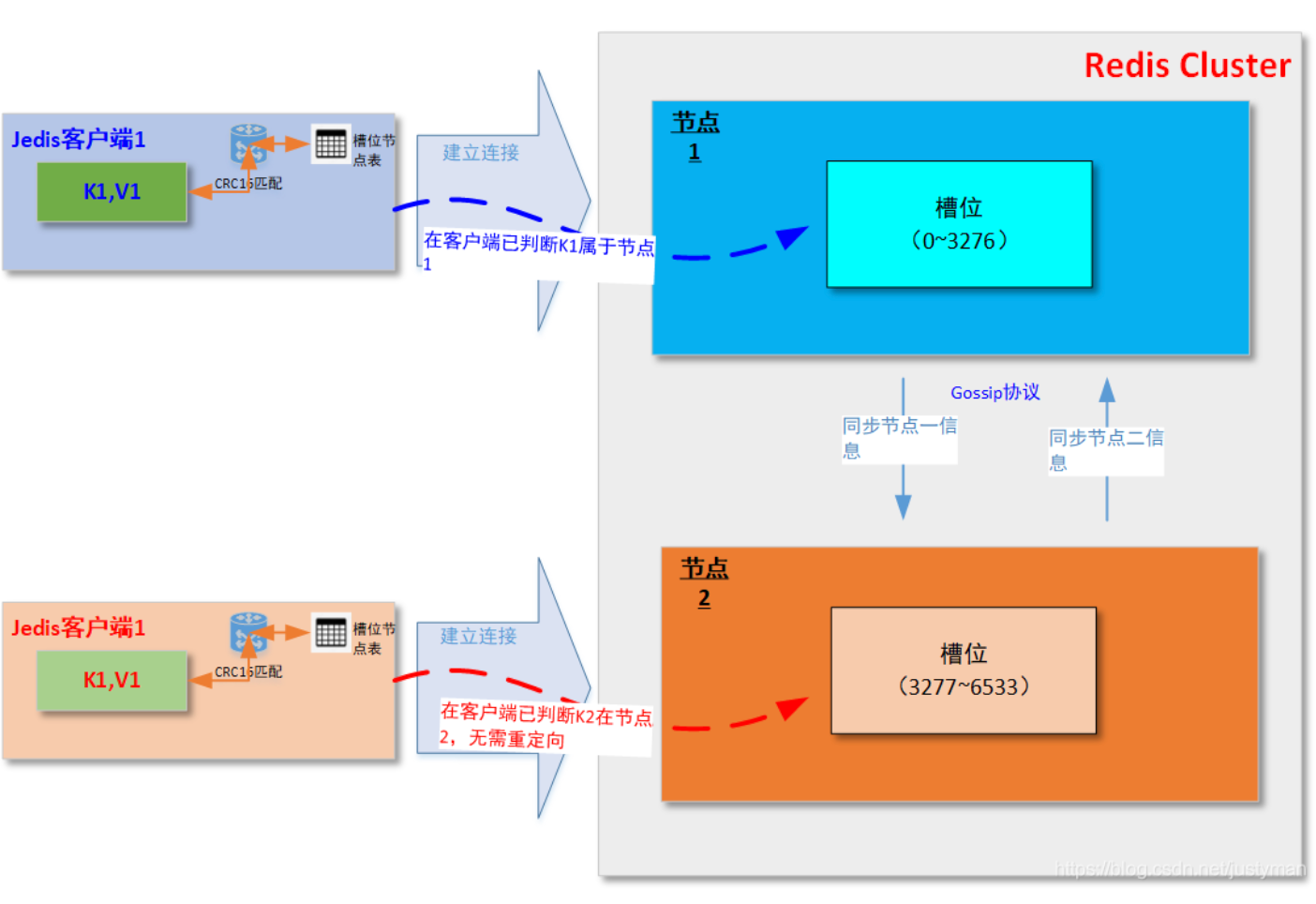
关于Smart Jedis这块,后面我另外起另外一篇文章再详细讲解吧。
数据迁移(节点扩缩容)
关于到业务数据量增长或节点宕机而导致节点的加入或退出的情况,上篇文章【 客户端分片(Redis Sharding)】提到过,Redis Sharding也跟哈希槽一样可以做分片,但是有个天生的缺陷就是只要集群内有新增或退出的节点时候对数据的读写是有一定影响的,但哈希槽这个方案可以在解决这个问题,具体它是怎么做到的呢?
区别于一致性哈希环空间,我这里把cluster哈希槽称为固定式哈希槽空间。从上图可以看出来,首先整个方案中有两个映射表【键值对/槽位映射匹配】、【槽位/节点映射】,这两个表把键值对与槽位的映射进行隔离解耦。这里意味着什么,大家知道吗?
首先,哈希槽空间是被固定死的(共16384个槽),因此不管物理节点怎么改变是不会影响CRC16(key)%16834计算出来的结果;
接着,因为具体的槽位是真正用来存储数据的。如果有节点加入和退出,我们只把所有原节点的部分槽位的数据迁移到新节点上,并更新【槽位/节点映射表】。整个数据迁移过程对客户端是透明的,具体的数据迁移过程又是怎样的呢?废话不多说,直接上动图吧。( 其中,节点间的配置信息的一致性是靠Redis Cluster Bus中的Ping和Pong报文来交换的;当有新节点时先通过meet报文请求集群中其他节点将其加入集群中,在成功加入后常规会通过Ping/Pong报文进行刷新信息,当然整个信息同步的关键在于内置的逻辑时钟epoch来维系)
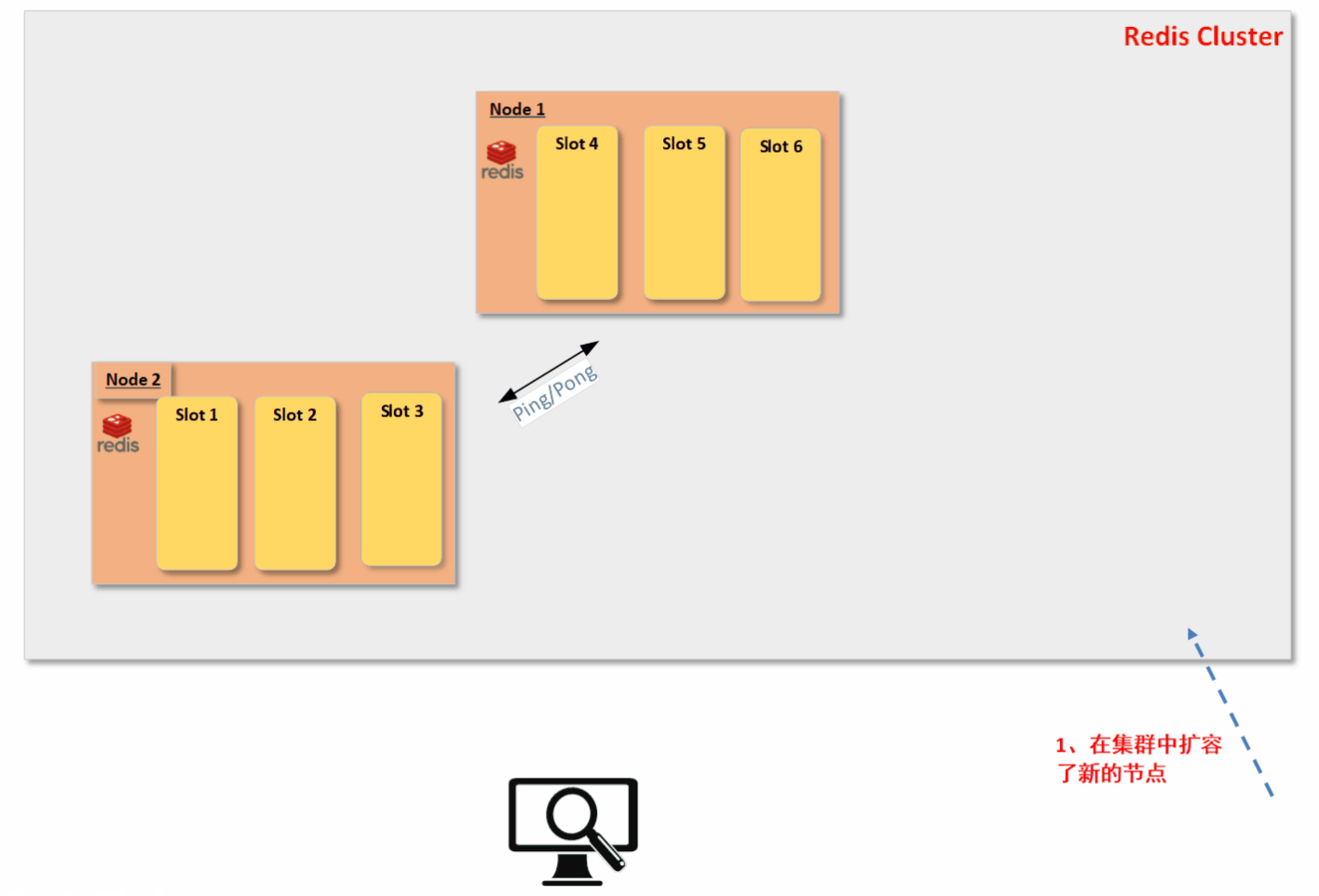
以上已经展示了在服务端是如何无缝的进行数据迁移?但是大家还没有考虑过一个问题,就是为什么新节点加入和旧节点退出时候为什么槽位是可以随意迁移的呢?我的理解是因为Redis Cluster可以做到数据的均匀离散性,这样的话实例节点中的哪些槽位存储哪些数据就显得没那么重要了(当然你自己在数据存储时候需要特殊规则存储数据的情况,那另当别论)。
数据离散性
大家一般会想到的不就是CRC16(key)%16384吗?但为什么?首先考虑CRC是一种单向散列函数(即哈希函数),散列函数有以下几种特性:
压缩映射:就是说任意长度的输入通过散列函数会被转换成固定长度的输出,即散列函数具有无限的定义域和有限的值域;
单向性:就是明文串S经过哈希后的hash(S)是不可逆的,即无法从hash(S)反推S出来的,因为上述的压缩映射特性,注定了S和hash(S)是多对一的关系;同步单向性也表明了整个散列的值域分布的随机性和均衡性。
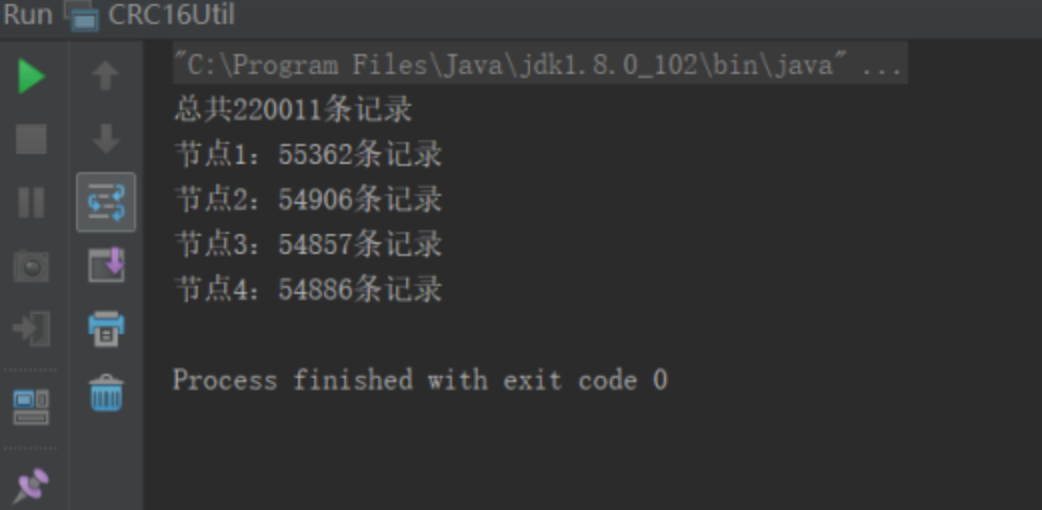
就是这里的 均衡性保证了,我们上面说的Redis Cluster节点的加入和退出时候导致的槽位迁移是不会出现所谓的“数据倾斜”的现象。这里我做了个简单验证。方法也很简单, 通过生成随机20W条数据,并通过CRC16进行散列运算并取余,从以下的结果可以发现基本每个槽位都大概有5500左右的记录。
import redis.clients.util.JedisClusterCRC16;
import java.util.Random;
public class CRC16Util {
/**
* 生成随机Key
*
* @length
* @return
*/
public String getRandomStringwithLength(int length){
String str="abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789";
Random random=new Random();
StringBuffer sb=new StringBuffer();
for(int i=0;i<length;i++){
int number=random.nextInt(62);
sb.append(str.charAt(number));
}
return sb.toString();
}
public static void main(String[] args) {
CRC16Util crc16Util = new CRC16Util();
int node1Count = 0;
int node2Count = 0;
int node3Count = 0;
int node4Count = 0;
int totalCount = 0;
//模拟生成20W条随机key,并通过CRC16(key)%16384进行模拟计算判断其槽位
//其中[1,4096]为槽1,[4097,8192)为槽2,[8193,12288)为槽3,[12289,16384)为槽4
for (int length=10;length<=20;length++){
for (int count=0;count<=20000;count++){
String key = crc16Util.getRandomStringwithLength(length);
int slot = JedisClusterCRC16.getCRC16(key) % 16384;
if (slot >=1 && slot <=4096){
node1Count++;
}else if(slot >=4097 && slot <8192){
node2Count++;
}else if(slot >=8193 && slot <12288){
node3Count++;
}else{
node4Count++;
}
totalCount = node1Count+node2Count+node3Count+node4Count;
}
}
System.out.println("总共" + totalCount + "条记录");
System.out.println("节点1:"+ node1Count + "条记录");
System.out.println("节点2:"+ node2Count + "条记录");
System.out.println("节点3:"+ node3Count + "条记录");
System.out.println("节点4:"+ node4Count + "条记录");
}
}
本文参考: